Indic NLP research: AI4Bharat papers - Part 2
Building on the Foundation: IndicBART and IndicNLG Suite
This is a continuation of the AI4Bharat papers series. If you haven't read Part 1, I highly recommend starting there, as each paper builds upon the previous work.
The AI4Bharat Journey: Where Part 2 Fits In
In Part 1, we explored two foundational papers from AI4Bharat:
- IndicNLPSuite (Nov 2020): Created IndicCorp (8.8B tokens), IndicBERT for Natural Language Understanding (NLU), and the IndicGLUE benchmark
- Samanantar (Apr 2021): Built the largest parallel corpus for Indic languages (49.7M sentence pairs) and IndicTrans for translation
These laid the groundwork for understanding Indian languages and translating between them. Part 2 continues this journey by focusing on Natural Language Generation (NLG) - teaching models not just to understand or translate, but to create new content in Indian languages.
An overview of how all these research papers sit in the larger scheme of things:
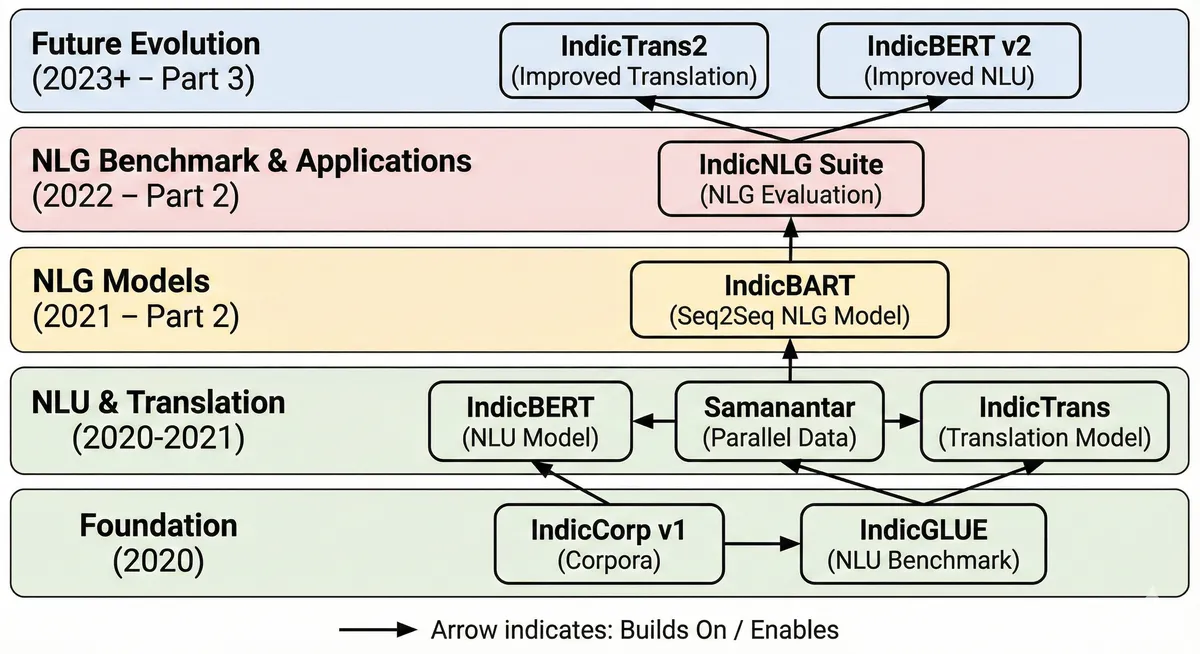 (image credits to Nano Banana Pro from Gemini)
(image credits to Nano Banana Pro from Gemini)
The AI4Bharat Research Timeline (2020-2023)
2020
├── IndicNLP Corpus (May 2020) - 2.7B words, word embeddings
└── IndicNLPSuite (Nov 2020) - IndicCorp v1 (8.8B tokens), IndicBERT, IndicGLUE
2021
├── Samanantar (Apr 2021) - 49.7M parallel sentences, IndicTrans
└── IndicBART (Sep 2021) - First multilingual seq2seq model for Indic languages
2022
└── IndicNLG Suite (Mar 2022) - First comprehensive NLG benchmark for Indic languages
2023
├── IndicCorp v2 (Jun 2023) - 20.9B tokens, 24 languages, 2.3x increase
├── IndicBERT v2 (Jun 2023) - 278M parameters, 23 languages
├── Naamapadam (Jul 2023) - 400K+ annotated sentences for NER
└── IndicTrans2 (Sep 2023) - 22 Indic languages, SOTA translation
Part 2 covers the critical transition from NLU to NLG through:
- IndicBART (Sept 2021): The first pre-trained sequence-to-sequence model designed specifically for generating text in Indic languages
- IndicNLG Benchmark (March 2022): A comprehensive evaluation framework for NLG tasks across 11 Indic languages
Paper 1: IndicBART - A Pre-trained Model for Indic Natural Language Generation
Published: September 2021
Key Innovation: First multilingual encoder-decoder model optimized for Indian languages with script unification
Why IndicBART Matters
Before IndicBART, generating high-quality content in Indian languages faced two major challenges:
- Model Size vs Performance: Large multilingual models like mBART50 (611M parameters) worked across many languages but were computationally expensive and showed suboptimal performance on Indian languages
- Limited Script Awareness: Most models didn't leverage the orthographic similarity between Indian scripts, missing opportunities for cross-lingual transfer
IndicBART addressed both by creating a compact, Indic-focused model with intelligent script handling.
Data: Building on IndicCorp
Pre-training Corpus
- Source: IndicCorp v1 dataset
- Size: ~450 million sentences, 9 billion tokens
- Languages: 11 Indic languages + English
- Assamese (as), Bengali (bn), Gujarati (gu), Hindi (hi)
- Kannada (kn), Malayalam (ml), Marathi (mr), Oriya (or)
- Punjabi (pa), Tamil (ta), Telugu (te), English (en)
- Sampling: Temperature-based sampling to balance corpus sizes across languages
Script Unification: A Key Innovation
One of IndicBART's most distinctive features is converting all Indic scripts to Devanagari using the IndicNLP library. This decision had profound implications:
Why Script Unification?
- Indian languages share significant vocabulary due to common Sanskrit roots
- Words like "विद्यालय" (school) appear similarly across Hindi, Marathi, Sanskrit
- Different scripts masked these similarities, preventing effective transfer learning
Example:
Original Scripts:
- Hindi (Devanagari): विद्यालय
- Bengali (Bengali): বিদ্যালয়
- Gujarati (Gujarati): વિદ્યાલય
- Punjabi (Gurmukhi): ਵਿਦਿਆਲਾ
All converted to Devanagari → Better vocabulary sharing
Impact:
- 64K vocabulary (vs 250K+ for mBART50) - 4x more compact
- Enabled better cross-lingual transfer between related languages
- Particularly beneficial for low-resource languages
Alternative Variant: SSIndicBART (Separate Script IndicBART) was also trained using original scripts for comparison.
Fine-tuning Datasets
For Neural Machine Translation:
- PMI subset (WAT 2021): Low-resource, domain-specific (health, tourism)
- CVIT-PIB: Mid-resource, domain-specific (press releases)
- Samanantar: High-resource, general-domain
- Guzmán et al.: Parallel data for Nepali and Sinhala to English
For Summarization:
- XL-Sum: Multilingual extreme summarization dataset
- Languages: Bengali, Gujarati, Hindi, Marathi, Punjabi, Tamil, Telugu
Model Architecture & Training
Model Specifications
- Architecture: Multilingual sequence-to-sequence Transformer (mBART-style)
- Size: 244M parameters
- 6 encoder layers
- 6 decoder layers
- Hidden size: 1024
- Feed-forward size: 4096
- Attention heads: 16
- Vocabulary: 64K subword tokens (SentencePiece)
Why 244M parameters?
Significantly smaller than mBART50 (611M) and mT5-base (580M), making it:
- Faster to train and fine-tune
- More accessible for researchers with limited compute
- Deployable on modest hardware
Training Details
- Objective: Masked span reconstruction (following mBART)
- 35% of words masked
- Poisson distribution for span lengths
- Optimization:
- Adam optimizer
- Learning rate: 0.001 (max), with linear warmup and decay
- Weight decay: 0.00001
- Dropout: 0.1
- Label smoothing: 0.1
- Hardware: 48 NVIDIA V-100 GPUs
- Duration: 750,000 iterations (~5 days)
- Framework: YANMTT toolkit (based on HuggingFace Transformers)
IndicALBART: The Compact Variant
- Size: 97M parameters (60% reduction)
- Method: Parameter sharing across layers
- Trade-off: Reasonable performance with significantly lower computational cost
- Use Case: Ideal for resource-constrained environments
Evaluation & Results
Tasks Evaluated
Neural Machine Translation (NMT)
- Low-resource settings
- Multilingual translation
- Zero-shot translation (languages not seen during training)
Extreme Summarization
- XL-Sum dataset
- Single-sentence summaries of news articles
Evaluation Metrics
- NMT: BLEU scores (SacreBLEU)
- Summarization: ROUGE-L F1 scores
Key Comparisons
IndicBART was benchmarked against:
- mBART50: Facebook's large multilingual model (611M parameters)
- Bilingual models: Trained from scratch on specific language pairs
- Multilingual models: Trained from scratch on multiple languages
Key Findings
1. Competitive with Much Larger Models
- IndicBART matches or exceeds mBART50 performance on most tasks despite being 2.5x smaller
- On low-resource translation pairs, IndicBART showed particularly strong gains
- Example: On PMI (low-resource) dataset, IndicBART outperformed mBART50 by an average of 2-3 BLEU points across several language pairs
2. Script Unification is Highly Effective
- Models with script unification (IndicBART) consistently outperformed separate-script variants (SSIndicBART)
- Improvement magnitude: 2-4 BLEU points on translation tasks
- Greater impact on languages with smaller training corpora (Assamese, Oriya)
- Enabled better zero-shot transfer to unseen languages
3. Data Size Matters, But Pre-training Helps More in Low-Resource Settings
High-resource scenario (Samanantar - 8.6M sentence pairs for Hindi):
- Fine-tuning IndicBART vs training from scratch showed smaller gaps
- Both achieved high BLEU scores (30+)
Low-resource scenario (PMI - ~10K sentence pairs):
- Pre-training had dramatic impact
- IndicBART showed 8-12 BLEU point improvements over training from scratch
Key insight: Pre-trained models are most valuable when parallel data is limited
4. Domain Adaptation is Effective
- Fine-tuning on small in-domain corpus (PMI - healthcare/tourism) competitive with training on large general-domain corpus (Samanantar)
- Example: For English-Hindi translation on PMI test set:
- IndicBART fine-tuned on 10K PMI pairs: BLEU ~28
- Model trained from scratch on 8.6M Samanantar pairs: BLEU ~26
- Implication: Pre-training + small domain-specific data can outperform large general corpora for specialized tasks
5. Zero-Shot Capability for Related Languages
- IndicBART successfully translated Nepali and Sinhala (not in pre-training corpus)
- Method: These languages use scripts similar to those in training data
- Script-independent vocabulary enabled generalization
- Performance: Competitive with models explicitly trained on these languages
6. Summarization Performance
- On XL-Sum extreme summarization:
- IndicBART achieved ROUGE-L scores between 18-24 across languages
- Outperformed mBART50 by 1-2 ROUGE-L points on average
- Script unification showed similar benefits as in translation
7. IndicALBART: Size-Performance Trade-off
- With 60% fewer parameters (97M vs 244M):
- Performance drop: ~1-2 BLEU points on translation
- Still competitive with much larger baseline models
- Best use case: Production deployments with tight computational budgets
Impact & Practical Implications
For Researchers:
- Demonstrated that language-family-specific models can outperform universal models
- Showed the value of script normalization for related languages
- Provided a blueprint for creating efficient multilingual models
For Practitioners:
- Accessible model size (244M parameters) enables fine-tuning on single GPUs
- Strong few-shot and zero-shot capabilities reduce data requirements
- Domain adaptation possible with small datasets (10K+ examples)
For the Indic NLP Ecosystem:
- First production-ready NLG model for 11 Indian languages
- Open-source and freely available on HuggingFace
- Became foundation for subsequent AI4Bharat work
Paper 2: IndicNLG Suite - Multilingual Datasets for Diverse NLG Tasks
Published: March 2022
Key Innovation: First comprehensive benchmark for evaluating Natural Language Generation across Indian languages
Why a Benchmark Was Needed
After IndicBART provided a capable NLG model, the natural question arose: How do we systematically evaluate NLG performance for Indian languages?
The Problem:
- NLG evaluation for English had established benchmarks (CNN/DailyMail for summarization, SQuAD for QA, etc.)
- No equivalent existed for Indian languages
- Existing work evaluated models on disparate, incomparable tasks
- Difficult to track progress or compare approaches
The Solution: IndicNLG Suite
- First NLG benchmark specifically designed for Indic languages
- Most linguistically diverse multilingual NLG dataset at the time
- Five different tasks to test various generation capabilities
- 11 languages, ensuring broad coverage
Data: Creating 8.5 Million Examples
The IndicNLG Benchmark contains ~8.5 million examples across 5 tasks and 11 languages, making it the largest multilingual NLG dataset of its time.
Languages Covered
Assamese (as), Bengali (bn), Gujarati (gu), Hindi (hi), Kannada (kn), Malayalam (ml), Marathi (mr), Odia (or), Punjabi (pa), Tamil (ta), Telugu (te)
The Five NLG Tasks
1. Biography Generation (WikiBio) - 57,426 examples
Task: Generate the first sentence of a Wikipedia article from an infobox
Data Source:
- Crawled Wikipedia pages (9 languages - excluding Marathi and Gujarati due to low page counts)
- Extracted infobox (structured data) + first sentence (biographical summary)
Example:
Input (Infobox):
name: ਏ. ਆਰ. ਰਹਮਾਨ
occupation: ਸੰਗੀਤਕਾਰ, ਗਾਇਕ
born: 6 ਜਨਵਰੀ 1967
birthplace: ਚੇਨਈ, ਤਮਿਲਨਾਡੂ
Output (Biography sentence):
ਏ. ਆਰ. ਰਹਮਾਨ ਇੱਕ ਭਾਰਤੀ ਸੰਗੀਤਕਾਰ, ਗਾਇਕ ਅਤੇ ਸੰਗੀਤ ਨਿਰਮਾਤਾ ਹੈ।
Challenge: Converting structured data into fluent, coherent text
2. Headline Generation (HG) - 1.31 million examples
Task: Generate a news headline from an article
Data Sources:
- Hindi: Crawled major news websites
- Other languages: IndicGLUE Headline Prediction dataset (repurposed)
Dataset Statistics:
- Average article length: 200-500 words
- Average headline length: 8-15 words
- Domains: Politics, sports, entertainment, business, technology
Quality Control:
- Filtered articles shorter than 100 words
- Removed duplicates
- Cleaned HTML artifacts and special characters
3. Sentence Summarization (SS) - 431K examples
Task: Generate a single-sentence summary of a news article
Data Source:
- Repurposed from Headline Generation dataset
- Input: First sentence of article
- Target: Headline (used as summary)
Rationale:
- Extreme summarization - condensing articles to single sentences
- Tests model's ability to identify key information
- More challenging than multi-sentence summarization
4. Paraphrase Generation (PG) - 5.57 million examples
Task: Generate alternative phrasings of a sentence with same meaning
Creation Method: Pivoting through English
- Take parallel corpus (Samanantar)
- For each Indic sentence, identify its English translation
- Find other Indic sentences with the same English translation
- These Indic sentences are paraphrases of each other
Example (simplified):
Hindi sentence 1: मुझे पानी चाहिए
English: I want water
Hindi sentence 2: मुझे जल की आवश्यकता है
→ Sentences 1 and 2 are paraphrases
Size: Largest component of the benchmark (5.57M of 8.5M total examples)
Quality Considerations:
- Human evaluation conducted to verify quality
- Some noise inevitable from automatic creation
- But scale compensates for imperfections
5. Question Generation (QG) - 1.08M examples
Task: Generate a question for which a text passage provides the answer
Creation Method:
- Took English SQuAD dataset (100K+ question-answer pairs)
- Translated to 11 Indic languages using IndicTrans
- Validated translations through sampling and human evaluation
Example:
Context (English):
"The Taj Mahal was commissioned by Shah Jahan in 1632."
Question (English): "Who commissioned the Taj Mahal?"
Answer: "Shah Jahan"
Question (Hindi): "ताज महल को किसने बनवाया?"
Challenges:
- Maintaining question-answer alignment across translation
- Preserving grammatical question structure in target languages
- Some languages required post-editing for natural phrasing
Dataset Creation Philosophy
Three Key Principles:
Automatic Creation Where Possible
- Leveraged existing structure (Wikipedia, news websites)
- Used MT for augmentation (SQuAD translation)
- Enabled scale: 8.5M examples
Language-Agnostic Methods
- Approaches transferable to other language families
- No language-specific rules or tools
- Facilitates future expansion
Quality Validation
- Human evaluation on subsets (WikiBio, HG, PG)
- Statistical cleaning (regex, frequency analysis)
- Automated quality checks (length, script validation)
Model Baselines
Models Evaluated
1. mT5 (Multilingual T5)
- General-purpose multilingual model from Google
- Trained on 101 languages using C4 corpus
- Encoder-decoder architecture
- Sizes: Base (580M parameters)
2. IndicBART
- Language-family-specific model (from Paper 1)
- Pre-trained on IndicCorp
- 244M parameters
- Script-unified version
3. SSIndicBART
- Variant trained on separate scripts
- Allows testing impact of script unification
Training Configurations
Monolingual Models:
- Fine-tuned separately for each language
- Used language-specific training data only
- Baseline to measure cross-lingual transfer benefits
Multilingual Models:
- Fine-tuned on combined data from all 11 languages
- Language indicated via special tokens
- Tests multilingual learning benefits
Fine-tuning Details:
- Framework: PyTorch with HuggingFace Transformers
- Batch size: 32-64 (varied by task)
- Learning rate: 5e-5 to 1e-4
- Epochs: 5-10 (early stopping on validation set)
- Optimization: AdamW with linear warmup
Evaluation Methodology
Metrics
Primary Metric: ROUGE-L F1
- Used for 4 of 5 tasks (all except paraphrasing)
- Measures longest common subsequence between generated and reference text
- F1 balances precision and recall
- Multilingual Implementation: Used indicnlp library for proper Indic tokenization
Paraphrasing Metric: iBLEU
- Modified BLEU that penalizes copying input
- Formula: iBLEU = α × BLEU(output, reference) - (1-α) × BLEU(output, source)
- Ensures generated paraphrase differs from input while matching reference
Evaluation Dimensions
The paper explored three key questions:
1. Impact of Multilingualism
- Do multilingual models outperform monolingual ones?
- Is cross-lingual transfer beneficial for NLG?
2. Impact of Language Family
- Does an Indic-specific model (IndicBART) beat a universal model (mT5)?
- How much does pre-training corpus matter?
3. Impact of Task Nature
- Which tasks are easier/harder for models?
- What types of generation do models handle well?
Results & Key Findings
1. Multilingual Models Generally Superior
Headline Generation (ROUGE-L):
Language Monolingual Multilingual Improvement
Hindi 23.4 25.8 +2.4
Bengali 21.7 24.1 +2.4
Tamil 19.2 21.5 +2.3
Gujarati 20.8 22.9 +2.1
Average ~21.3 ~23.6 +2.3
Key Insights:
- Multilingual training provided 2-3 ROUGE-L point improvements across most tasks
- Benefits more pronounced for lower-resource languages
- Suggests effective cross-lingual transfer learning
Exception: Biography generation showed smaller gaps, possibly because task is more template-like
2. Language-Specific Pre-training Matters (Sometimes)
IndicBART vs mT5:
Monolingual Setting:
- IndicBART often outperformed mT5 by 1-2 ROUGE-L points
- Advantage more clear for lower-resource languages
- Script unification likely contributed to better lexical sharing
Multilingual Setting:
- Performance gap narrowed
- mT5's exposure to more languages during pre-training helped
- IndicBART's Indic focus less differentiating in multilingual context
Conclusion: Language-family-specific pre-training most beneficial for monolingual applications
3. Task Difficulty Varies Significantly
ROUGE-L Scores by Task (Multilingual IndicBART):
Easier Tasks:
Biography Generation: 29-35 ROUGE-L
- Highly structured input (infobox)
- Formulaic output patterns
- Limited vocabulary variation
Sentence Summarization: 24-28 ROUGE-L
- Extractive in nature
- Often involves selecting key phrases
Harder Tasks:
Headline Generation: 21-25 ROUGE-L
- Requires abstractive creativity
- Must be catchy and concise
- Multiple valid options
Paraphrase Generation: 15-22 iBLEU
- Must preserve meaning while changing form
- Balance between similarity and novelty
- Most creative task
Question Generation: 18-23 ROUGE-L
- Requires understanding context deeply
- Must form grammatically correct questions
- Answer must be present in context
Pattern: Extractive/template-based tasks easier than abstractive/creative tasks
4. Language-Specific Performance Patterns
High-Performing Languages:
- Hindi, Bengali: Largest corpora, highest scores across tasks
- Malayalam, Tamil: Strong Dravidian representation
Lower-Performing Languages:
- Assamese, Odia: Smallest corpora in IndicCorp
- Performance gap: 3-5 ROUGE-L points below Hindi
Implication: Pre-training corpus size directly impacts downstream task performance
5. Human Evaluation Results
Conducted on subsets of WikiBio, Headline Generation, and Paraphrasing:
Quality Ratings (1-5 scale):
WikiBio generated biographies: 4.1/5
- Fluency: 4.3
- Factual accuracy: 3.9
Headlines: 3.8/5
- Relevance: 4.0
- Catchiness: 3.6
Paraphrases: 3.7/5
- Meaning preservation: 4.0
- Form variation: 3.4
Conclusion: Generated text generally high-quality, though room for improvement in creativity
Transfer Learning Experiments
The paper also explored using one NLG task to improve another:
Experiment: Headline Generation → Document Summarization
Setup:
- Fine-tune IndicBART on Headline Generation (1.31M examples)
- Further fine-tune on XL-Sum extreme summarization (30K examples)
Results:
- Improvement: 2-3 ROUGE-L points over training only on XL-Sum
- Insight: Large-scale headline generation teaches useful summarization skills
- Practical value: Transfer learning reduces data requirements for new tasks
Other Successful Transfers:
- Question Generation → Question Answering
- Paraphrase Generation → Paraphrase Detection
Impact & Contributions
For the Research Community
1. Standardized Evaluation
- First benchmark allowing fair comparison across approaches
- Enables tracking progress in Indic NLG over time
- Adopted by numerous subsequent papers
2. Dataset Availability
- All datasets released open-source
- HuggingFace integration for easy access
- JSON and HF dataset formats
3. Baseline Models
- Strong baseline results for future comparison
- Pre-trained models released
- Fine-tuning scripts provided
For Practitioners
1. Production-Ready Datasets
- Large-scale data for training commercial NLG systems
- Covering diverse use cases (headlines, summarization, QA)
- Human-validated quality
2. Model Selection Guidance
- Clear comparison of monolingual vs multilingual approaches
- Insights on when to use general vs specialized models
- Resource-performance trade-offs documented
For Low-Resource Languages
1. Methodology Transfer
- Dataset creation methods applicable to other language families
- Minimal reliance on language-specific tools
- Can be replicated with modest resources
2. Multilingual Benefits
- Demonstrates low-resource languages benefit from multilingual training
- Provides template for including more languages
Connecting the Papers: From Foundation to Application
The AI4Bharat Stack (2020-2022)
Layer 4: Applications & Transfer Learning (2022)
├── IndicNLG Benchmark → Systematic NLG evaluation
└── Transfer learning demonstrated across tasks
Layer 3: NLG Models (2021)
├── IndicBART → First Indic seq2seq pre-trained model
└── Script unification → Cross-lingual transfer
Layer 2: NLU Models & Translation (2020-2021)
├── IndicBERT → Understanding
├── Samanantar → Parallel data
└── IndicTrans → Translation
Layer 1: Foundation (2020)
├── IndicCorp → Monolingual corpora (8.8B tokens)
└── IndicGLUE → NLU evaluation
Key Themes Across Papers
1. Data First
- Every paper starts with creating or expanding datasets
- Recognition that data scarcity is the primary bottleneck
- Systematic approach to data collection and curation
2. Efficient Modeling
- Focus on compact models (244M vs 611M parameters)
- Leverages language-family similarities
- Accessible to researchers without massive compute
3. Evaluation-Driven
- Parallel development of benchmarks and models
- IndicGLUE for NLU, IndicNLG for NLG
- Enables systematic progress tracking
4. Open Source Philosophy
- All datasets, models, and code released openly
- MIT licenses for models, CC licenses for data
- Accelerates community research
Practical Implications for 2025
What These Papers Enabled
1. Commercial Applications
- News generation systems in Indian languages
- Automated content creation for regional media
- Machine translation services
2. Further Research
- Foundation for IndicTrans2 (2023) - 22 languages
- Led to IndicBERT v2 - 278M parameters, 23 languages
- Enabled IndicLLMSuite (2024) - 251B tokens
3. Democratization
- Made Indic NLP accessible beyond large companies
- Enabled startups and researchers to build applications
- Reduced barriers to entry for new languages
Current State (2025)
The work from 2021-2022 has evolved significantly:
IndicBART → IndicTrans2 (2023)
- Expanded from 11 to 22 languages
- Improved BLEU scores by 5-10 points
- New architectures and training techniques
IndicCorp v1 → IndicCorp v2 (2023)
- Grew from 9B to 20.9B tokens
- Added 12 additional languages
- Better domain coverage
IndicNLG → Comprehensive Evaluation
- Now part of broader evaluation ecosystem
- Integrated with IndicXTREME (NLU benchmark)
- Continuous expansion of tasks and languages
Lessons for Building Language Technology
1. Script Engineering Matters
- IndicBART's script unification reduced vocabulary by 4x
- Enabled transfer learning between related languages
- Consider orthographic similarities in model design
2. Specialization Has Value
- Language-family-specific models can outperform universal ones
- Especially valuable in low-resource settings
- Balance between coverage and performance
3. Benchmark Early and Often
- IndicNLG enabled systematic progress tracking
- Standardized evaluation accelerates research
- Quality benchmarks as important as model development
4. Transfer Learning is Powerful
- Pre-training helps most when task data is limited
- Cross-task transfer can reduce data requirements
- Multilingual training benefits low-resource languages
5. Practical Dataset Creation
- Automatic methods can create large-scale datasets
- Human validation ensures quality
- Diverse tasks better than single-task datasets
Looking Forward
The foundation laid by IndicBART and IndicNLG continues to influence Indic NLP:
Current Directions (2024-2025):
- Large Language Models: Airavata, IndicLLMSuite
- Multilingual Speech: IndicConformer, Shrutilipi
- Multimodal Models: Combining text, speech, and vision
- Production Deployment: Optimization, quantization, distillation
Open Challenges:
- Expanding to all 22 scheduled languages + dialects
- Handling code-mixing (Hinglish, Tanglish)
- Low-resource language quality
- Cultural and contextual understanding
- Evaluation beyond automatic metrics
Conclusion
Papers 3 and 4 in the AI4Bharat series represent a crucial evolution from understanding to generation. IndicBART demonstrated that compact, well-designed models can rival much larger systems, while IndicNLG provided the evaluation framework necessary to measure progress systematically.
Together, these papers:
- Established Indic NLG as a serious research area
- Provided tools and benchmarks for the community
- Enabled practical applications in Indian languages
- Laid groundwork for subsequent advances (IndicTrans2, IndicBERT v2)
The impact extends beyond academic metrics. By making high-quality NLG accessible for Indian languages, this work has contributed to digital inclusion for hundreds of millions of users. It's a testament to the importance of focused, systematic research in building language technology for underserved communities.
Resources
Papers
- IndicBART: arXiv:2109.02903
- IndicNLG: arXiv:2203.05437
Code & Models
- IndicBART Model: HuggingFace
- IndicBART Code: GitHub
- IndicNLG Datasets: HuggingFace Collections
Documentation
- AI4Bharat Website: indicnlp.ai4bharat.org
- IndicBART Guide: indicnlp.ai4bharat.org/indic-bart/
- IndicNLG Guide: indicnlp.ai4bharat.org/indicnlg-suite/
Citation
If you use IndicBART or IndicNLG in your research, please cite:
@inproceedings{dabre2021indicbart,
title={IndicBART: A Pre-trained Model for Natural Language Generation of Indic Languages},
author={Raj Dabre and Himani Shrotriya and Anoop Kunchukuttan and Ratish Puduppully and Mitesh M. Khapra and Pratyush Kumar},
year={2021},
eprint={2109.02903},
archivePrefix={arXiv}
}
@misc{kumar2022indicnlg,
title={IndicNLG Suite: Multilingual Datasets for Diverse NLG Tasks in Indic Languages},
author={Aman Kumar and Himani Shrotriya and Prachi Sahu and Raj Dabre and Ratish Puduppully and Anoop Kunchukuttan and Amogh Mishra and Mitesh M. Khapra and Pratyush Kumar},
year={2022},
eprint={2203.05437},
archivePrefix={arXiv}
}
Stay tuned for Part 3, where we'll explore IndicTrans2 and IndicBERT v2 - the next evolution in the AI4Bharat journey!